

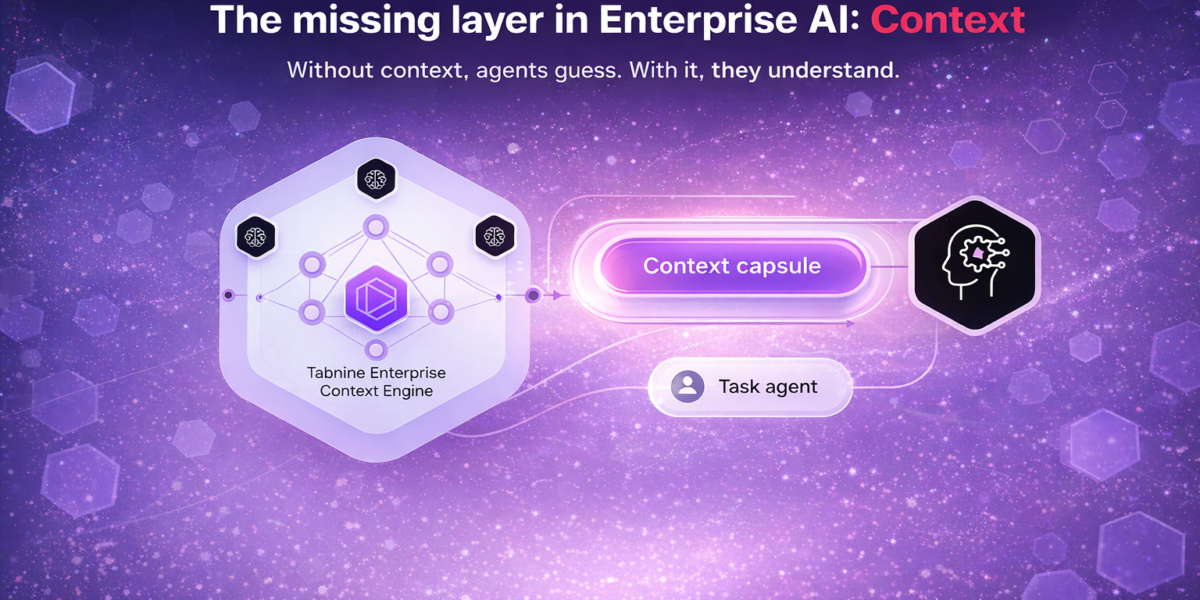
A year ago, the pitch for AI coding tools was simple: generate more code, faster. Autocomplete on steroids. The differentiator was the model — which one produced the best function body, the most accurate completion, the fewest hallucinations.
That pitch is over.
Code generation is commoditizing. As of early 2026, the gap between the top model and the fifth-ranked model on SWE-bench Verified is under 4 percentage points and closing quarter over quarter. Pricing per million tokens has dropped roughly 10x in eighteen months. Every IDE ships some form of code generation. Every cloud vendor bundles it. Within two years, AI code generation will be what syntax highlighting is today — expected, undifferentiated, and not something anyone pays for separately.
This is not a problem. It is a premise. The interesting question is: what comes after code generation becomes table stakes?
The wrong answer
The industry’s current default answer is: build a better agent. Make it more autonomous. Give it more tools. Let it run longer. Demo it solving a GitHub issue end-to-end.
This framing has a structural flaw. An autonomous coding agent operating without organizational context is a highly productive engineer with no memory of the team’s past. It doesn’t know your architecture decisions. It doesn’t know that you rejected a specific library last quarter for licensing reasons. It doesn’t know that the pattern it’s about to introduce caused an incident six months ago. It doesn’t know your dependency policy, your naming conventions, or who owns the service it’s modifying.
It ships fast. And it ships wrong.
More autonomy, without more context, produces technical debt at a rate that post-hoc review cannot absorb. The math is illustrative but directionally correct: if your agents generate even 5x the volume of code changes, and your review process stays the same, your review bottleneck grows by the same factor. No team scales review linearly with generation. The result is either slower shipping (defeating the purpose) or lower review quality (accumulating risk).
The scarce resource shifted
For most of the history of AI-for-code, the scarce resource was intelligence — the model’s ability to produce correct code. That scarcity is dissolving. Models are good enough, and getting better fast.
The new scarce resource is organizational knowledge.
Every engineering organization carries a dense, largely implicit body of knowledge: architecture decisions, post-incident learnings, dependency policies, coding standards, ownership boundaries, security constraints. This knowledge lives in git history, design docs, Slack threads, Jira tickets, incident reports, and the heads of senior engineers. It is what separates code that works from code that works here.
No current coding agent has meaningful access to this layer. They see your repository. Sometimes they see your open files. They do not see your decisions, your norms, or your history. They are, at best, context-unaware.
This gap is not a feature request. It is a category boundary.
What actually comes next
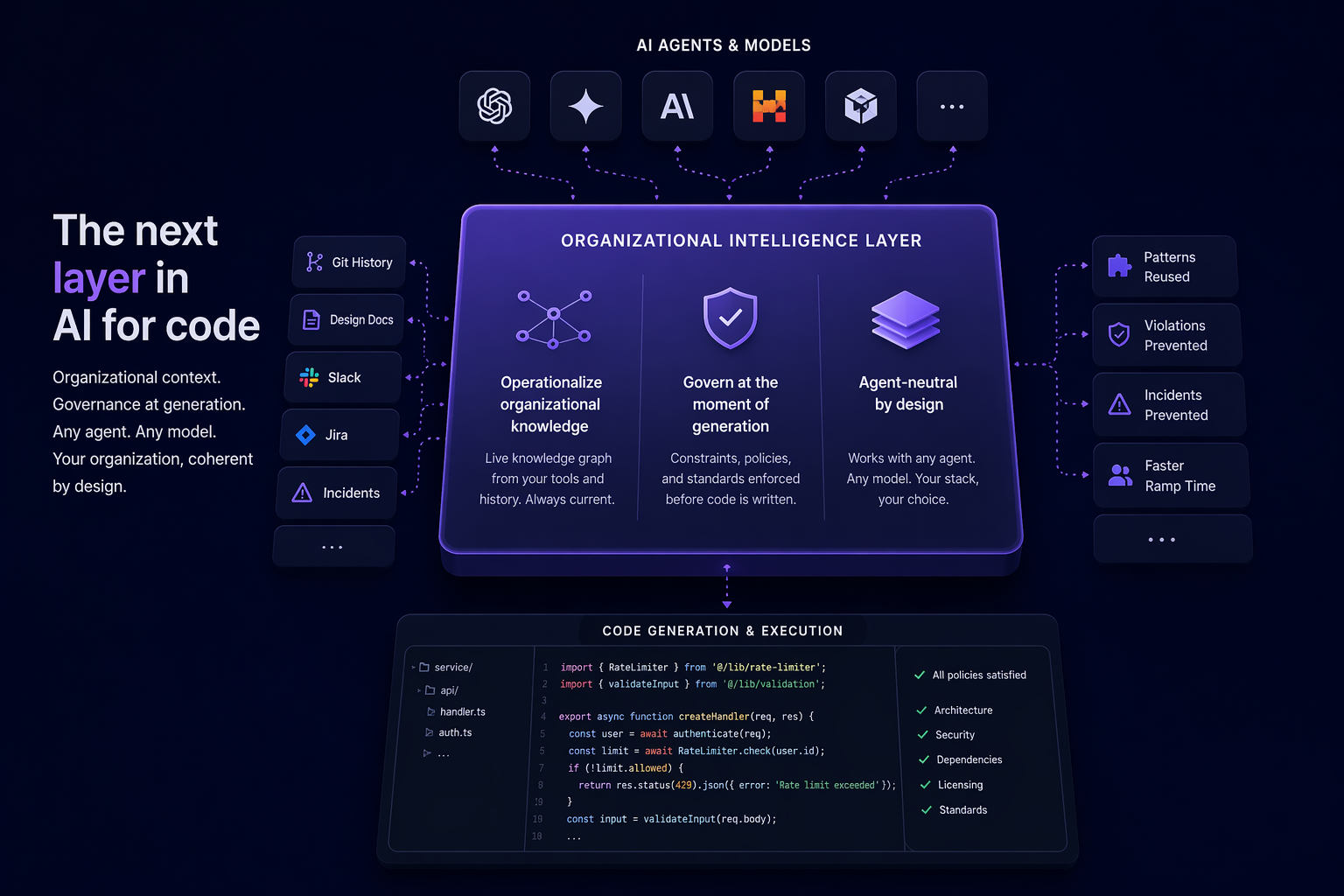
The next category in AI-for-code is not “better agent.” It is the layer between what the organization wants and how agents deliver it.
This layer has three properties:
It operationalizes organizational knowledge. Not as a static wiki agents can search, but as a live knowledge graph — decisions, patterns, incidents, dependencies, ownership — extracted continuously from the systems engineering teams already use. The agent queries it at generation time. It stays current because it ingests continuously, not because someone maintains it.
It governs at the moment of generation. Architecture constraints, security policies, licensing rules, and quality standards are enforced before the code is written — not at PR review, not by a post-hoc scanner, not by a human who may or may not catch the violation. Governance moves left, to the point where it can actually scale with generation volume.
This is closer to my research in program synthesis than most people realize. In synthesis, you constrain the space of programs that can be generated, rather than filtering bad programs after generation. Governance at generation applies the same principle to organizational constraints.
It is agent-neutral. The execution layer — which model writes the code, which agent orchestrates the workflow — is increasingly fungible. The organizational layer is not. The platform that hosts any agent is more durable than the platform that is one agent. Enterprise buyers understand this: they will not bet their stack on one model vendor’s roadmap.
These three properties — organizational context, governance at generation, and agent neutrality — define the category. A product that delivers all three is a platform. A product that delivers any two is a feature inside someone else’s platform.
The measurement changes too
If the category shifts, the metrics shift with it.
The metrics that defined AI coding assistants — lines generated, acceptance rate, completions per day — measure the old category. They answer the question “how much code did the AI write?” That question is becoming irrelevant as generation commoditizes.
The new metrics answer a different question: “is the AI making the organization better at building software?”
Decisions preserved per developer. Patterns reused across teams. Incidents prevented because the agent knew the organization’s history. Architecture violations caught at generation, not at review. New-engineer ramp time. These are the numbers that matter when the bottleneck is no longer generation but organizational coherence.
The bottleneck moved. The metrics — and the category — have to move with it.