

Overview
Requirements Planning
Planning is where engineering velocity is either created or destroyed.
When a product manager writes a PRD or a sprint plan, they’re not just documenting features. They’re synthesizing inputs from across the organization—architecture, existing code, dependencies, ownership, standards, and operational constraints. It’s a complex, high-stakes process that determines how efficiently a team can execute.
AI has started to play a role here, but most approaches focus on generating documents. That’s not the real problem. Writing isn’t the bottleneck—understanding is.
Effective planning requires assembling the right context every time. When AI can do that reliably, it stops being a writing tool and becomes a system for producing planning artifacts that are actually executable.
The problem
Why AI Planning Breaks Down
Most AI-driven planning fails because it operates on incomplete and shallow context.
Typical workflows rely on what’s in a Jira ticket or a prompt. But that’s only a small fraction of what defines a requirement. Critical information lives elsewhere—in the codebase, in architectural decisions, in documentation, in ownership models, and in operational constraints.
Without that broader context, AI produces plans that look reasonable but fall apart in execution. Dependencies are missed. Requirements conflict with existing systems. Tasks aren’t aligned to how the codebase is structured or who owns it. Testing and deployment considerations are incomplete or incorrect.
The downstream impact is predictable. Teams spend cycles correcting requirements, reworking implementations, and resolving issues that should have been caught during planning. Over time, this leads to slower delivery, increased technical debt, and failed releases.
The core issue isn’t that AI can’t generate plans—it’s that it doesn’t understand the system those plans are meant to operate within.
The Solution
Context-Driven Requirements Planning
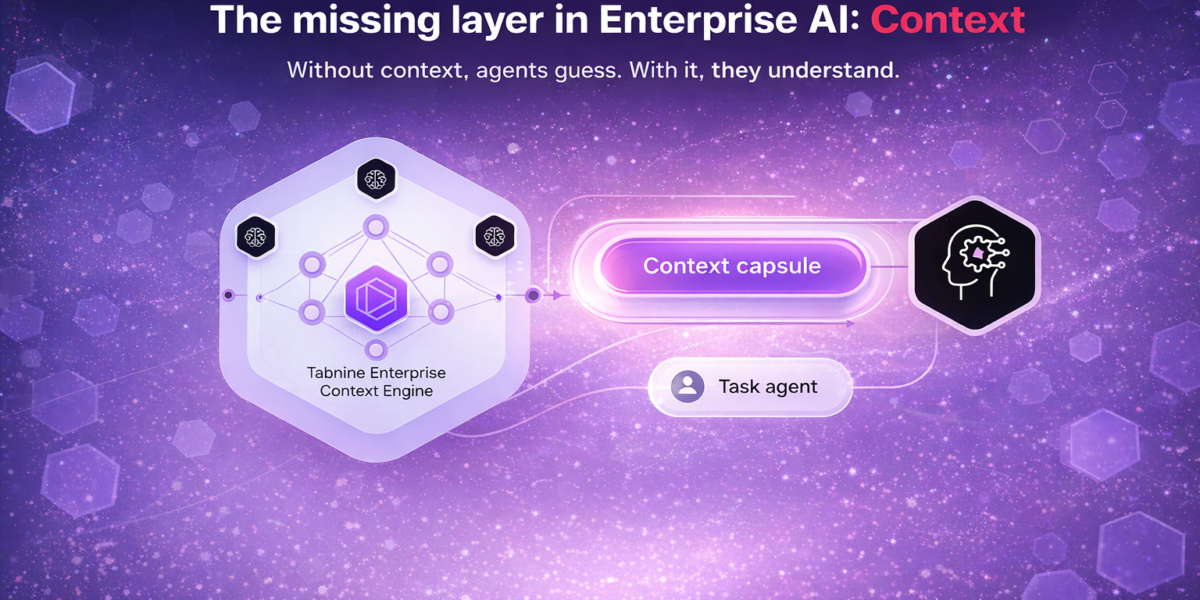
The context engine changes planning by giving AI a structured understanding of how the organization actually builds software.
It ingests and connects signals from across the environment—code, documentation, Jira, architectural decisions, and operational data—into a unified knowledge graph. This graph doesn’t just store information; it models the system itself, including service boundaries, dependencies, data flows, ownership, and constraints.
When planning begins, AI doesn’t rely on a single ticket or static input. It pulls from this graph, assembling a complete and current picture of the system. It can see how a requirement maps to existing code, what dependencies it introduces, which teams own the relevant components, and what standards must be followed.
Using that context, it generates planning artifacts that are grounded in reality. A PRD that reflects actual architectural constraints. User stories with acceptance criteria aligned to real system behavior. A testing plan that accounts for dependencies and edge cases. A deployment checklist that fits the existing CI/CD pipeline.
Just as importantly, the output is connected back to the system. Tasks are mapped to specific components and files. Work is aligned with team ownership. Requirements are reconciled against what already exists, reducing ambiguity and eliminating gaps.
This turns planning from a manual, error-prone activity into a repeatable, system-driven process. It can be triggered automatically from workflow events, run on demand for specific features, or scaled across entire backlogs.
That’s the shift. From AI that writes plans, to AI that understands the system those plans are for. From incomplete requirements, to executable plans grounded in the full reality of the organization.