

I’ve sat in this meeting more times than I can count. We demo the agent — code generation, context, governance. The CISO listens, then asks one question: “Where does my code go?” If the answer involves an external API, the meeting is over.
This is not a niche concern. It is the default reality for regulated enterprises evaluating AI coding tools. Financial services, healthcare, defense, public sector — organizations operating under FedRAMP, HIPAA, SOX, ITAR, or internal data-sovereignty policies cannot send source code and prompts to external endpoints. Full stop. The constraint is not negotiable, not waivable, and not satisfied by a SOC 2 badge on the vendor’s marketing page.
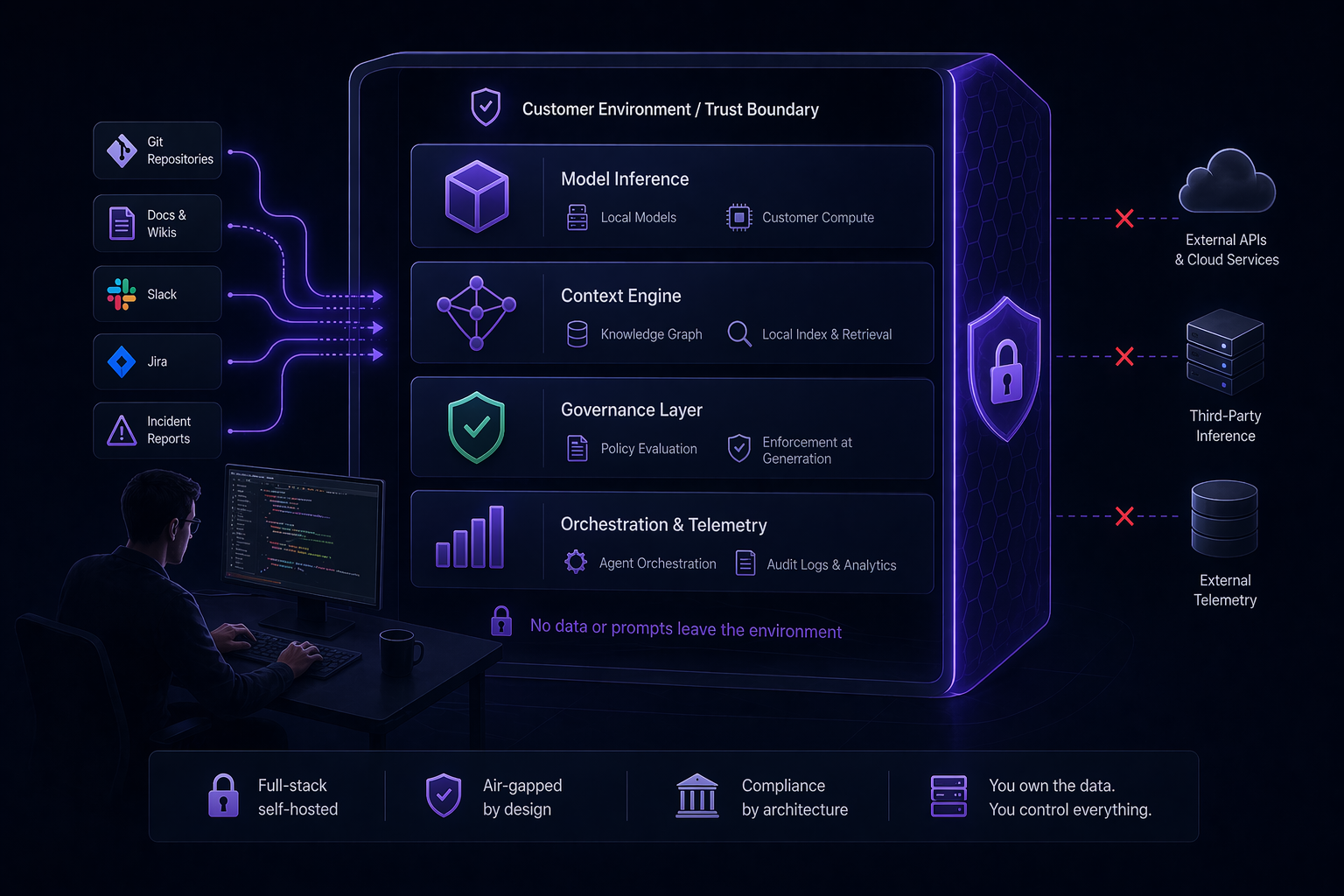
Today, Tabnine’s self-hosted deployment is generally available. The full stack — model, Context Engine, governance layer — runs inside the customer’s trust boundary. Air-gapped, VPC, on-prem, cloud-of-choice. No code leaves the environment. No prompts leave the environment. No telemetry leaves the environment unless the customer explicitly configures it to.
This is not a premium tier. It is the architecture.
The gap between “enterprise-ready” and actually deployable
Most AI coding tools follow a predictable pattern when they encounter regulated buyers. First, they offer a cloud-hosted “enterprise” plan with SSO, audit logs, and a data processing agreement. When that fails the security review, they offer a self-hosted model — a container you can run locally that handles inference. When the buyer asks about the rest of the stack, the conversation gets uncomfortable.
The problem is that a self-hosted model is not a self-hosted product. A coding agent is not just a model. It is a model plus a context layer plus a governance layer plus an orchestration framework plus telemetry plus policy enforcement. If the model runs locally but context retrieval calls an external API, code still leaves the boundary. If governance rules are evaluated in the vendor’s cloud, prompts still leave the boundary. If telemetry phones home, metadata about your codebase — file paths, function names, usage patterns — still leaves the boundary.
Partial self-hosting does not satisfy the constraint. It creates a more complex version of the same problem, one that is harder to audit and easier to misconfigure.
Full-stack self-hosted: what actually runs locally
Tabnine’s self-hosted deployment puts the entire operational stack inside the customer’s environment. Concretely:
Model inference. The AI models run on the customer’s hardware — GPU nodes in their data center, their VPC, or their cloud account. No inference calls cross the network boundary. The customer controls the compute, the model versions, and the update cadence.
Context Engine. The organizational knowledge graph — the layer that connects the agent to architecture decisions, coding standards, dependency policies, incident history, and team norms — runs locally. Indexing happens inside the boundary. Retrieval happens inside the boundary. The organizational knowledge that makes the agent useful never leaves the environment where it was created.
Governance layer. Policy evaluation — which patterns are permitted, which libraries are approved, which security constraints apply — executes locally. Governance decisions are made inside the trust boundary, not by calling an external policy service. Policy enforcement at generation time is essentially a verification problem — you are checking properties of code before it exists in the repository. This is closer to my research in program analysis than most people realize, and it is why I am confident the approach scales.
Orchestration and telemetry. Agent orchestration, usage analytics, and audit logs all run locally. The customer owns the data. The customer controls retention. No usage metadata is transmitted externally.
The result is a deployment where the trust boundary is the customer’s boundary, completely. There is no ambient external connectivity required. The system operates air-gapped.
Deployment modes
We support air-gapped, VPC, and hybrid deployment — the details are in our deployment docs. The point isn’t the menu of options. The point is that none of them require degraded capabilities, because the stack was designed for local-first operation.
Why the architecture has to be native
A common objection: why can’t any AI coding tool just “offer a self-hosted option”? Technically, any vendor could package their stack into containers and ship it. The issue is architectural.
Products designed for cloud-first operation tend to assume abundant, low-latency connectivity to central services. Context retrieval hits a central index. Model inference routes through a central gateway. Governance rules are pulled from a central policy store. Telemetry streams to a central analytics pipeline. When you try to move these products behind a firewall, you either replicate all the central services (complex, fragile, expensive) or you accept a degraded experience (features missing, latency increased, updates delayed).
Tabnine’s stack was designed for local-first operation. Context indexing is local by default. Policy evaluation is local by default. The system does not assume external connectivity for any core operation. Most competitors started cloud-native and are now trying to unbundle their stack into containers that run behind a firewall. We went the other direction: local-first from the start, which means there is no central service dependency to replicate or stub out. That is an architectural decision you cannot retrofit without a rewrite.
This matters operationally. Customers who run Tabnine air-gapped do not call support to troubleshoot intermittent connectivity to an external service. There is no external service. The failure modes are local, the diagnostics are local, and the customer’s infrastructure team can reason about the system using the same tools they use for everything else.
Compliance implications
Self-hosted deployment directly addresses requirements across multiple compliance frameworks:
Data residency is satisfied by construction — code, prompts, and organizational knowledge remain in the jurisdiction and environment the customer controls. HIPAA’s data-at-rest and data-in-transit requirements are met within the customer’s existing encryption and access-control infrastructure. FedRAMP authorization boundaries are cleaner when the AI tooling runs inside the boundary rather than requiring an external SaaS authorization. ITAR and EAR constraints on technical data are satisfied because no technical data is transmitted to a third party.
The compliance argument is not “we meet these frameworks.” It is “the architecture eliminates the categories of risk these frameworks exist to address.” Data cannot be exfiltrated to a third party if there is no connection to a third party.
The trust boundary argument
The deeper point is about trust boundaries, not features.
Every organization has a trust boundary — the perimeter within which it controls data, access, and computation. Security architecture is fundamentally about maintaining the integrity of that boundary. When an AI coding tool operates outside the trust boundary, it introduces a dependency that the organization cannot fully audit, cannot fully control, and cannot fully secure. The vendor becomes a trust dependency.
For some organizations, that dependency is acceptable. For regulated enterprises, it is not. And the number of organizations that fall into the “not acceptable” category is growing, not shrinking, as AI tools gain access to more sensitive data — not just code, but architecture decisions, incident history, internal policies, and organizational knowledge.
Self-hosted deployment eliminates the vendor as a trust dependency for data handling. The customer trusts Tabnine’s software — they audit it, they test it, they approve it through their procurement process. But they do not trust Tabnine’s infrastructure with their data, because they do not have to.
This is the trust model that makes deployment feasible in regulated environments. It is also, increasingly, the trust model that non-regulated enterprises prefer.