

Eran Yahav, CTO of Tabnine
Every enterprise I talk to has the same stack: a coding agent, a pile of governance rules that run too late, and an organizational knowledge problem no one has named yet. These are not three problems. They are one architecture, assembled wrong. Over the past seven weeks, I have taken this apart, layer by layer. This piece puts it back together.
Seven capabilities. One platform.
Listed as features, what we have described over the past seven weeks looks like a product roadmap. An organizational knowledge graph. Self-hosted deployment. Agent-neutral execution. Policy enforcement at generation time. Code quality as a security control. Supply chain verification at the moment of dependency selection.
Listed as layers, they look different.
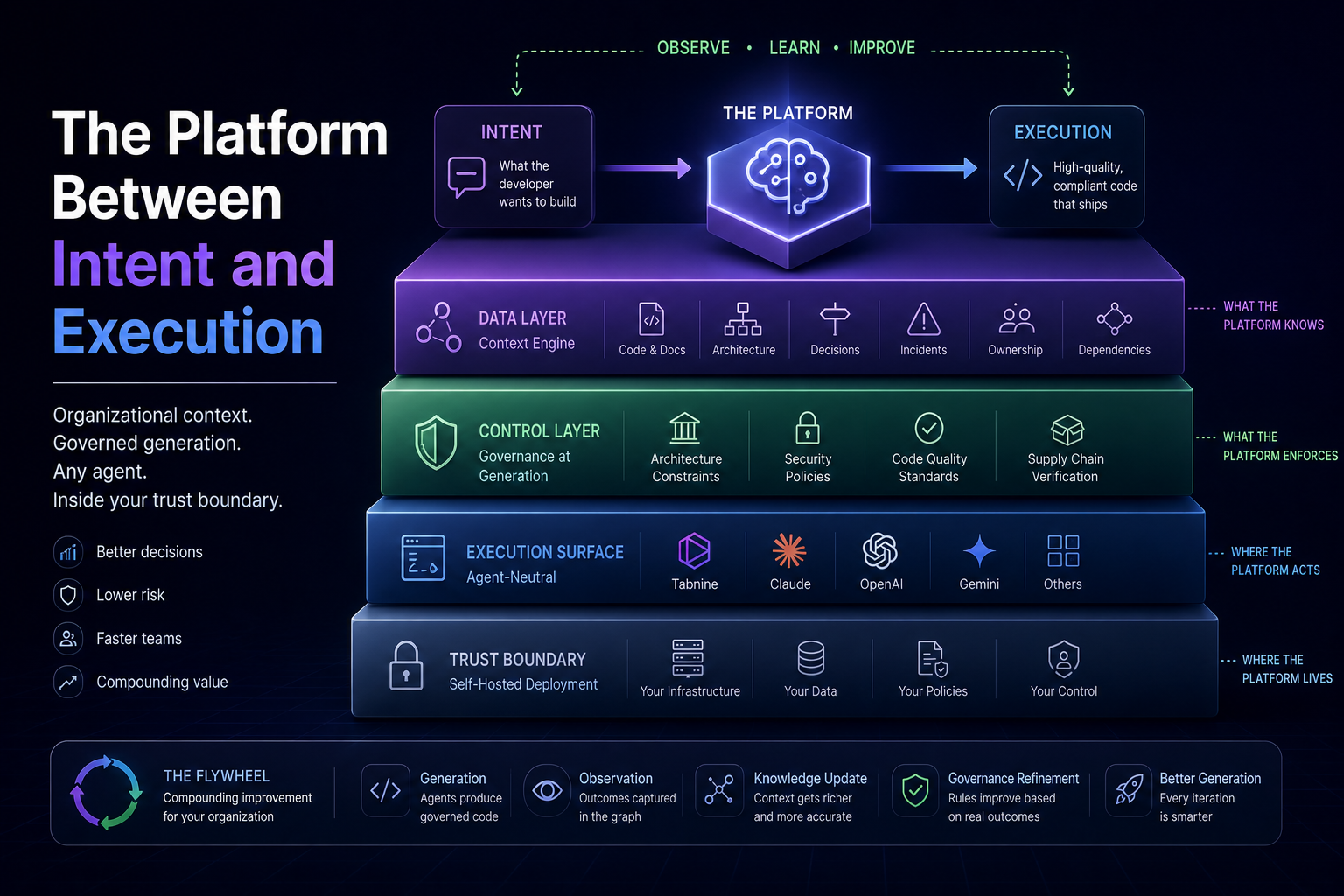
The data layer is the Context Engine — a continuously updated knowledge graph of your organization’s engineering artifacts, decisions, incidents, ownership, and dependencies. It is what the platform knows.
The control layer is governance at generation — architecture constraints, security policies, quality standards, and supply chain rules enforced before code is written. It is what the platform enforces.
The execution surface is agent-neutral — any model, any agent, any orchestration framework, governed uniformly. It is where the platform acts.
The trust boundary is self-hosted deployment — the entire platform, all three layers above, running inside the customer’s environment. It is where the platform lives.
These layers are not independent products bundled together. They are structurally dependent. Governance without organizational context is generic — it can enforce universal rules but not organization-specific ones. Context without governance is informational — it can surface knowledge but not enforce it. Both without agent neutrality are coupled to a single execution path. All three without self-hosted deployment are unusable by the customers who need them most.
The platform is the composition. Remove a layer and you have a different, lesser thing.
The flywheel
A platform earns its name by compounding. Here is how this one compounds.
Agents generate code. The Context Engine observes outcomes — which patterns are accepted, which are rejected in review, which cause incidents, which get reused. The knowledge graph updates. Governance rules refine. The next generation is better informed.
Each element is concrete. Early deployments are beginning to produce measurable signal on this loop. When a reviewer rejects an agent-suggested pattern and the rejection is captured in the graph, every future generation in that context benefits. When an incident is linked to a dependency and the supply chain layer updates its risk model, every future dependency selection benefits. When a new engineer onboards and the platform already encodes the team’s conventions, their ramp time shortens.
The critical property: this flywheel is per-customer. The knowledge graph is yours. The governance rules are yours. The improvement trajectory is specific to your organization. Two companies using the same platform will diverge in capability over time, because their organizations are different. The platform gets better for you the more you use it.
This is structurally different from a coding agent that improves by training on public data. That improvement is shared across all customers equally. It raises the floor. The organizational flywheel raises your ceiling.
The metrics that matter now
The measurement framework for AI coding tools was built for the old category. Lines generated. Acceptance rate. Completions per day. Time saved per task.
These metrics answer one question: how much code did the AI produce? When generation was the bottleneck, this was the right question. Generation is no longer the bottleneck.
The new metrics answer a different question: is the AI making the organization better at building software?
Decisions preserved per developer. When an agent generates code that reflects a prior architecture decision without the developer having to recall or enforce it manually, that is a preserved decision. In a 500-person engineering organization with years of accumulated decisions, the number of decisions silently enforced per day is a direct measure of organizational coherence.
Patterns reused across teams. Not copy-paste reuse. Structural reuse — the agent in team B generating code that follows the pattern team A established, because the knowledge graph connects them. Cross-team consistency without cross-team coordination overhead.
Incidents prevented. The agent does not introduce a pattern that caused a previous incident, because the graph links patterns to outcomes. This is measurable: the rate of pattern-related incidents before and after the platform encodes the relevant history.
Architecture violations caught at generation. Not at PR review. Not by a post-hoc scanner running in CI. At the moment of code creation. The earlier a violation is caught, the cheaper it is to fix. At generation time, the cost is zero — the code is never written.
New-engineer ramp time. A new engineer working with a platform that already encodes the team’s conventions, ownership boundaries, and historical decisions produces organization-consistent code faster than one who must learn these through osmosis and code review feedback.
These metrics are harder to measure than acceptance rate. They require instrumentation that most organizations have not built yet. But they measure what actually matters: whether AI is accumulating organizational value or organizational debt.
What qualifies as this category
We are defining a category. Not naming it yet with certainty — “governed AI development” is the working term, though the precise label matters less than the requirements. Here is what the category requires.
An organizational knowledge layer that is live, structured, and cross-source. Not a documentation search engine. Not RAG over the repository. A knowledge graph that resolves entities across systems, maintains relationships, and updates continuously. If the platform does not know your organization’s decisions, ownership, and history, it cannot govern on your organization’s behalf.
Governance that operates at generation time. Post-hoc scanning is necessary but insufficient. By the time a scanner flags a violation, the code exists, a developer has context-switched, and fixing it is an interruption. Governance at generation means the violation is prevented, not detected. The economics are fundamentally different.
Agent and model neutrality. The organizational layer must outlast any individual agent or model. If your governance only works with one vendor’s agent, you have not adopted a platform — you have adopted a feature that locks you in. The platform governs the execution surface; it does not compete within it.
Self-hosted deployment as architecture, not add-on. For regulated enterprises — financial services, healthcare, defense, public sector — the organizational knowledge graph contains the most sensitive information in the engineering organization: architecture decisions, security constraints, incident details, ownership maps. This data cannot leave the trust boundary. A platform that requires exfiltrating organizational knowledge to a vendor’s cloud is disqualified for a large fraction of the enterprise market.
A compounding feedback loop. The platform must get better per-customer over time. If it delivers the same value on day 300 as on day 30, it is a tool, not a platform. The flywheel — generation, observation, knowledge update, governance refinement — is the difference.
Products that meet some of these requirements exist. Products that meet all of them define the category.
I should be direct about maturity. The Context Engine, self-hosted deployment, and agent-neutral architecture are GA — shipping and in production. Governance at generation, code-quality enforcement, and supply-chain checking are in development, at varying stages. The architecture is real. Not every layer is complete. I have been transparent about status in each post in this series, and I am transparent here: this is a platform being built, not a platform being marketed.
What we will not do
A category claim requires negative space. Here is ours.
We will not compete on model quality. The model layer is commoditizing. Competing on who has the best code generation model is competing on a diminishing margin. We will integrate the best available models — ours and others — and focus on the layers above.
We will not build another IDE. The developer’s environment is their choice. The platform integrates with IDEs; it does not replace them. Fragmenting developer experience to capture surface area is a short-term play with long-term costs.
We will not chase autonomy theater. The demo where an agent solves a GitHub issue end-to-end, unsupervised, with no organizational context, is impressive and misleading. It optimizes for the demo, not for the deployment. Real enterprise autonomy requires trust. Trust requires governance. Governance requires context. We are building the stack that makes meaningful autonomy possible, not the demo that simulates it.
We will not claim to replace engineers. AI that is organizationally aware augments engineering judgment. It encodes and distributes what senior engineers know. It does not eliminate the need for that knowledge — it makes it available to more people, at higher speed, with lower loss.
Where this goes
Seven weeks ago, I wrote that the era of code generation as a product category is ending. That remains true. The question was never whether AI would write code — it would, and it does, and it will do so better every quarter. The question was whether AI would write code that reflects what your organization actually wants.
That question is an architecture question. It requires a data layer that knows the organization. A control layer that enforces its standards. An execution surface that is open. A deployment model that the organization trusts.
It requires a platform.
The test is simple. Can your platform enforce an architecture constraint at the moment an agent generates code, using context from your last three incidents, without sending either the constraint or the incident data outside your network? If the answer is no, you do not have a platform. You have a tool with a roadmap.