


There’s a shift happening across engineering teams right now.
Developers are spending less time searching, planning, and wiring things together, and more time prompting. You open your IDE, type a few lines, and code appears. It feels fast, almost frictionless. For a while, it genuinely changes how you work.
And to be fair, it works. Teams are shipping faster. Backlogs move. People feel more productive.
But if you watch closely over a few weeks, something else starts to show up.
Code gets rewritten more often than expected. Pull requests go through multiple rounds of review. Things that looked finished turn out to need another pass. Not because the AI is wildly wrong, but because it is just slightly off in ways that matter.
What’s happening is subtle. The system is helping you move faster, but it is not helping you move in the right direction.
It doesn’t break. It drifts.
One of the tricky things about these tools is that they rarely fail in obvious ways. Most of the time, the output is close enough to look correct.
But it doesn’t quite fit your architecture. It doesn’t reuse the right service. It follows a pattern that works, just not the one your team has standardized on.
So you adjust it. Then adjust it again. Then leave a comment in the pull request explaining what needs to change.
Individually, these are small corrections. Collectively, they add up to something much larger: rework becoming the default mode of operation.
The loop nobody tracks
If you sit next to someone using these tools, you’ll see the same pattern repeat.
They prompt, get a response, refine it, and try again. Sometimes they get to a good answer quickly. Often they don’t.
So they add more detail. They steer the model. They correct it toward something they already had in mind.
It feels like progress because something is always happening. But underneath, every task has quietly turned into a loop of exploration.
That loop has a cost. Not just in tokens, although that matters more than most teams realize, but in time and attention. You are no longer just solving the problem. You are guiding a system that does not fully understand the environment it is operating in.
What the AI doesn’t know
The core issue is not that the AI is unreliable. It is that it is unaware.
It does not know your architecture.
It does not know which services already exist.
It does not know your internal standards, your conventions, or the tradeoffs your team has already made.
So it fills in the gaps.
Sometimes it guesses well. Sometimes it does not. Most of the time it gets close enough to look right, which is what makes this harder to catch.
Now someone has to step in and reconcile that gap between what was generated and what actually fits.
When rework becomes the job
Talk to any senior engineer after a few weeks of using these tools and you start to hear a consistent pattern.
They are not spending their time writing code faster. They are spending their time reviewing, correcting, and reshaping what was generated.
Pull requests stretch out.
Small tasks take multiple passes.
Code that looked finished turns out to be a draft.
The work has shifted.
Less creation. More correction.
And correction is slower.
The illusion of speed
From the outside, it still looks like acceleration. More code is being produced. More activity is happening.
But activity is not the same as progress.
If every task requires multiple iterations to land correctly, then the system is not actually faster. It is just busier.
And the cost compounds over time. More tokens. More review cycles. More back and forth between human and machine.
Most of it invisible unless you know where to look.
When it scales, it becomes risk
In smaller projects, this is manageable.
In enterprise systems, it is something else entirely.
Now the code touches real dependencies, real constraints, and real consequences. A small misalignment is no longer just a quick fix. It can mean breaking an existing service, violating an architectural boundary, or introducing something that passes review but creates problems later.
The issue is not dramatic failure. It is quiet misalignment that slips through and shows up weeks later.
What’s missing is not more intelligence
The default response to these problems is to reach for better models, larger context windows, or more aggressive prompting strategies.
But that misses the point.
The problem is not a lack of intelligence. It is a lack of understanding.
Understanding of how your systems are structured.
Understanding of what already exists.
Understanding of how your organization actually builds software.
Without that, every task starts from zero, no matter how powerful the model is.
A more familiar way to think about it
Imagine bringing a new engineer onto your team.
They are capable. They write code quickly. But they do not yet know your systems.
At first, they move fast. Then you start correcting them. Not because they are doing something unreasonable, but because they do not yet have the context to make the right decisions.
Now imagine that engineer never builds that understanding. Every task starts fresh. Every decision requires correction.
That is what most AI systems look like today.
Now compare that to an engineer who already understands your architecture, your services, and your standards. They do not just move fast. They move correctly.
That difference is not about speed. It is about context.
Where this leads
The first wave of AI coding tools optimized for generation. That unlocked speed, and it mattered.
The next phase is about alignment. Making sure that what gets generated actually fits the systems it is meant to operate in.
Because in real engineering environments, speed only matters if it leads somewhere useful.
From generation to understanding
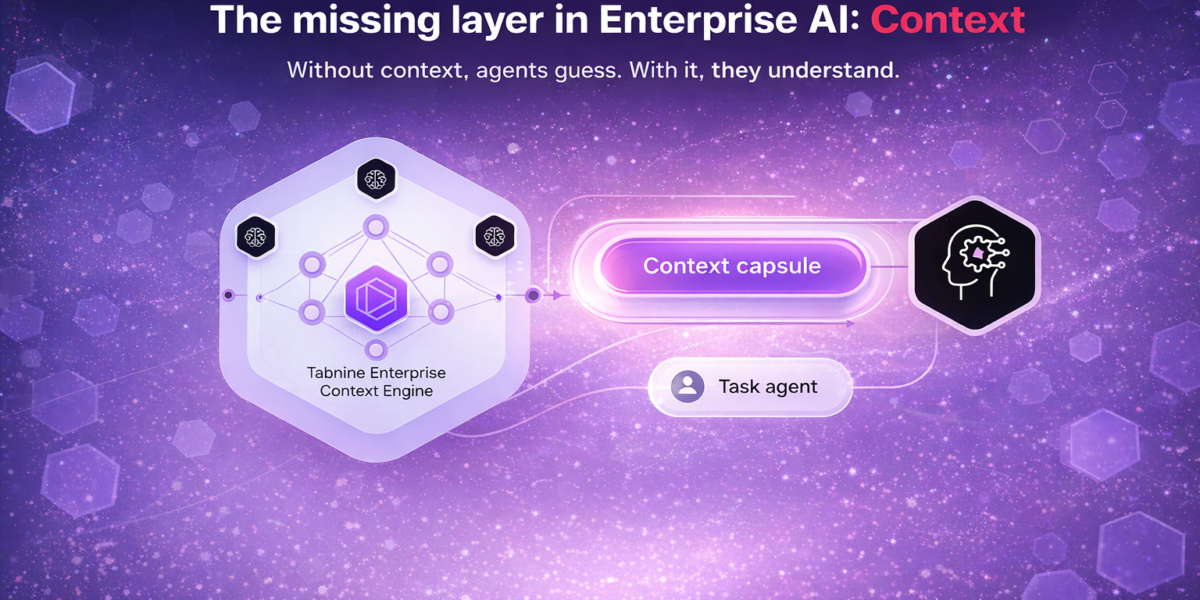
This is the gap the Tabnine Context Engine is designed to close.
Instead of treating every task as a blank slate, it gives AI systems structured knowledge of the environment they operate in. Repositories, services, dependencies, standards, and the relationships between them become part of how the system reasons, not something it has to guess.
The impact is straightforward. Fewer iterations. Less rework. More first pass acceptance. Lower token consumption because the system is not exploring blindly.
More importantly, it changes how teams work with AI.
You spend less time steering and correcting, and more time actually building.
That is the shift from generation to understanding. And that is where the real gains start to show up.