

A coding agent wrote a perfectly valid API endpoint last week. It called the billing service synchronously from the orders service — something our team banned after an incident in Q3. The code compiled. It passed tests. It would have caused the same cascading failure in production. The agent didn’t know about the incident. It had no way to know.
This is the problem the Tabnine Context Engine is designed to solve.
The problem is not what the agent sees — it’s what it doesn’t
Your coding agent can see your repository. It can see your open files. Some can search across your codebase. This is necessary and insufficient.
What the agent does not see: the decision your team made six months ago to stop using a specific ORM because of performance issues in production. The incident that taught you not to call service B synchronously from service A. The fact that the payments module is owned by a team that requires security review for any external-facing change. The naming convention your principal engineer established three years ago that no one documented but everyone follows.
This knowledge exists. It is dense, largely implicit, and distributed across git history, design documents, Slack conversations, Jira tickets, incident reports, and the heads of senior engineers. It is what makes the difference between code that compiles and code that belongs in your system.
Most coding agents today operate with minimal organizational context at best.
The result is predictable. The agent produces code that is syntactically correct, functionally plausible, and organizationally wrong. It introduces patterns your team abandoned. It creates dependencies your architecture explicitly avoids. It duplicates services that already exist under different names. A human reviewer catches some of this. Not all of it. Not at the volume agents are starting to produce.
Why “RAG on your repo” doesn’t solve this
The obvious response is retrieval-augmented generation over the codebase. Index the repository, embed the chunks, retrieve relevant context at generation time. Several tools do this. It helps with local context — finding similar functions, understanding nearby code.
It does not solve the organizational knowledge problem, for three reasons.
First, the knowledge that matters most is not in the code. Architecture decisions live in RFCs and design docs. Incident learnings live in post-mortems and Slack threads. Ownership boundaries live in team wikis and service catalogs. Dependency policies live in security review tickets. Code search finds code. It does not find decisions.
Second, even when the knowledge is in the code, it requires interpretation. A git log shows that someone refactored module X eight months ago. It does not explain why. A code search finds three different patterns for the same operation. It does not tell you which one is current. Raw retrieval returns text. Understanding requires structure.
Third, retrieval is stateless. Each query starts from scratch. There is no persistent model of how entities in your organization relate to each other — which services depend on which, who owns what, which decisions constrain which components, which incidents affected which systems. Without that structure, every agent invocation is an amnesiac starting over.
What the Context Engine is
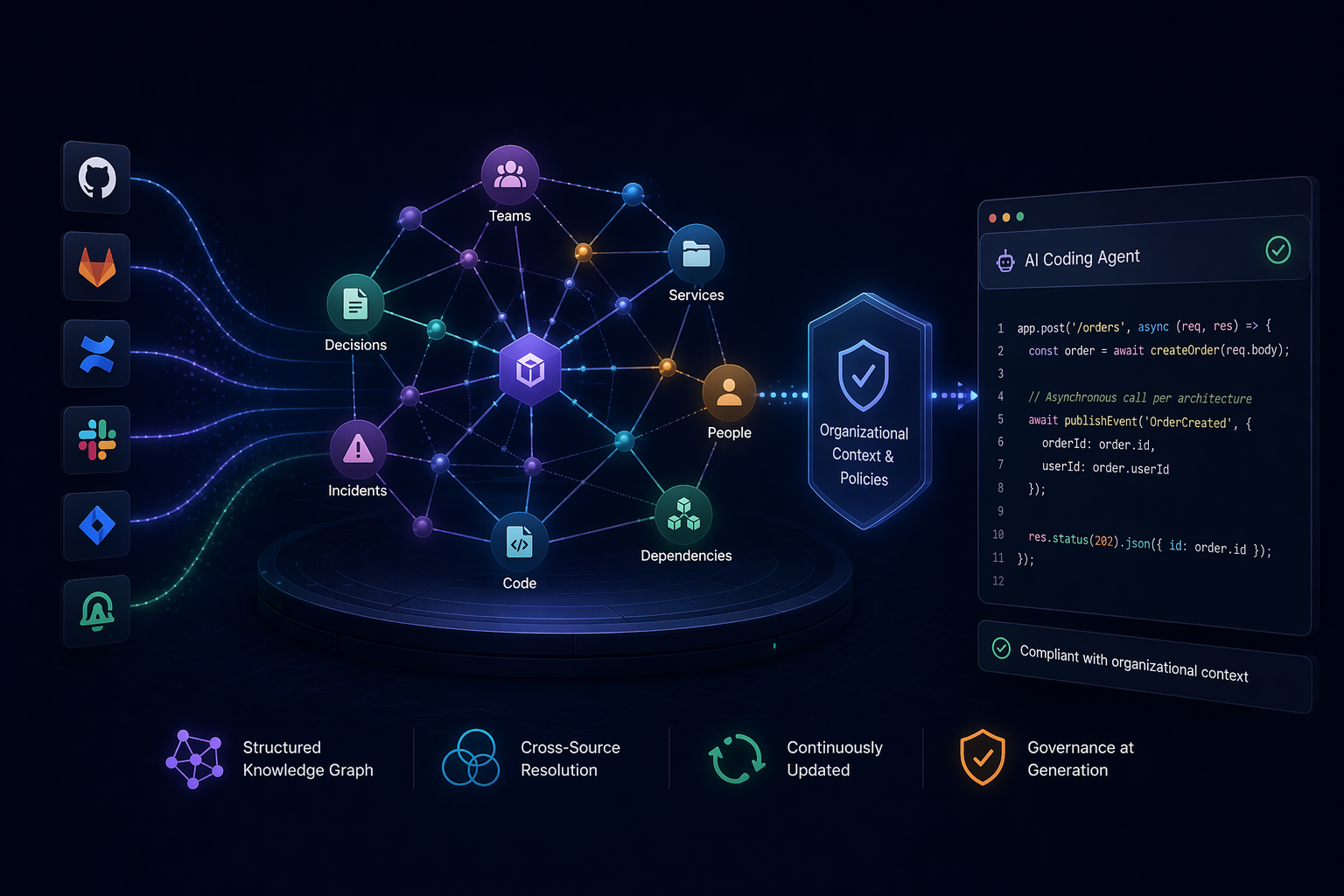
The Context Engine is Tabnine’s organizational knowledge graph. It is not a search index. It is a structured graph of engineering artifacts: code entities, architectural decisions, incidents, people, services, dependencies, and the relationships between them.
It ingests continuously from the systems your teams already use — git repositories, documentation platforms, messaging systems, issue trackers, incident management tools. It extracts entities and relationships, resolves them across sources, and maintains a live graph that agents can query at generation time.
Three properties define it.
It is structured, not retrieved. The graph contains typed entities (services, teams, decisions, incidents, dependencies) and typed relationships (owns, depends-on, caused-by, supersedes, constrains). When an agent asks “what constraints apply to this service?”, the answer traverses a graph. It does not search a text index and hope the right paragraph surfaces.
It is cross-source. A single engineering decision may appear as a comment in a pull request, a paragraph in a design document, a Jira ticket, and an offhand remark in Slack. The Context Engine resolves these into one entity with provenance from multiple sources. The agent sees the decision, not four fragments.
It stays current without maintenance. The graph updates continuously as new commits land, new documents are written, new incidents are filed. No one curates it. No one maintains a knowledge base. The graph reflects the organization’s actual state because it reads from the same systems the organization uses to operate.
Two ideas that do the real work
Underneath the product, two technical ideas carry most of the weight.
Entity resolution across heterogeneous sources. Engineering knowledge is scattered across systems that do not share schemas, identifiers, or vocabularies. The same service might be called “payment-service” in the codebase, “Payments” in Jira, “payment-svc” in the incident tracker, and “the payments thing” in Slack. The same person might appear as a GitHub handle, an email address, and a first name. Resolving these into canonical entities — and maintaining that resolution as new data arrives — is the core technical problem. We solve it through a combination of deterministic matching (shared identifiers where they exist) and learned resolution (where they don’t). The learned component builds on the same intuition behind code-representation research: names are noisy but structural context is stable. Two references point to the same entity when their relational neighborhoods converge, even if their surface names diverge. The graph is only as useful as its entity resolution is accurate.
Contextual relevance at query time. A knowledge graph with tens of thousands of entities is useless if the agent retrieves the wrong ones. When an agent is generating code for a specific file in a specific service, the Context Engine computes relevance by traversing the graph from the current working context — the file, its service, its dependencies, its owners, its recent incidents, its governing decisions. This is fundamentally different from embedding similarity. Two documents can be semantically similar but organizationally irrelevant. A decision about database connection pooling in the billing service is irrelevant to the payments service, even though both mention databases. Graph traversal knows this. Vector search does not.
Why this works
The Context Engine changes what is possible at generation time. Three concrete examples.
An agent generating a new API endpoint in the orders service queries the Context Engine and learns: this service is owned by the commerce team, it has a hard dependency on the inventory service but must not call the billing service directly (per an architecture decision from Q3), its APIs follow a specific versioning scheme (per team convention), and a recent incident traced to synchronous cross-service calls means all new external calls must be async. The agent generates code that accounts for these constraints. Without the graph, it would generate plausible code that violates at least one of them.
A developer asks an agent to add a caching layer. The Context Engine surfaces a decision from eight months ago: the team evaluated three caching approaches, chose one, and documented the rationale. The agent uses the chosen approach. Without the graph, it picks whatever approach the base model favors — which may or may not match what the team decided.
A security-sensitive change touches a service with PII handling requirements. The Context Engine identifies the ownership boundary and the compliance constraints attached to that service. Governance rules (which we will detail in a future post) can act on this information before the code is written. Without the graph, the agent treats every service the same.
These are not hypothetical scenarios. They are the kinds of mistakes that experienced engineers catch in review — when they catch them. As agent-generated code volume increases, the fraction that gets caught decreases. The Context Engine moves organizational knowledge from the reviewer’s head into the generation process itself.
What this means
The practical consequence: agent-generated code that violates organizational constraints should be caught at generation time, not at review time and not in production. The Context Engine is the first component of that architecture. It gives agents access to the organizational knowledge that previously existed only in the heads of senior engineers — structured, queryable, and current.