

AI coding assistants are quickly moving beyond autocomplete. They are becoming agents that can explain systems, modify code, generate tests, reason across repositories, and help developers navigate large software environments.
That shift has made context one of the most important problems in enterprise AI.
For an AI assistant to be useful inside a large engineering organization, it needs more than the file currently open in an IDE. It may need to understand related repositories, internal APIs, architecture documents, issue trackers, service ownership, coding standards, security policies, deployment history, runbooks, and business logic spread across multiple systems.
This is where knowledge graphs have become part of the conversation. They are valuable because they can model relationships between entities: services, repositories, APIs, teams, documents, tickets, infrastructure, and more. A graph can show that one service depends on another, that an API is owned by a specific team, or that a repository implements a particular business capability.
That structure matters. It gives AI systems a richer map of the software environment than keyword search or isolated embeddings can provide.
But a knowledge graph is not the same thing as a context engine.
A knowledge graph helps represent knowledge. A context engine helps operationalize context for AI systems.
That distinction matters.
What Knowledge Graphs Do Well
Knowledge graphs are especially useful when the problem is relationship modeling.
In an enterprise software environment, important information is rarely contained in a single place. A customer onboarding workflow, for example, might involve frontend code in one repository, backend services in another, API contracts stored separately, architecture documentation in Confluence, tickets in Jira, ownership data in a service catalog, and security requirements in an internal policy system.
A knowledge graph can connect those pieces.
It can model relationships such as:
– Service A depends on Service B
– Service B exposes API C
– API C is owned by Team D
– Team D maintains Repository E
– Repository E implements Feature F
– Feature F supports Business Process G
This is a meaningful advancement for AI assistants. Instead of treating every repository, document, and service as a disconnected artifact, a graph can expose the structure behind the system.
That helps an AI assistant reason across software boundaries. It can make it easier to find related code, understand dependencies, identify owners, and surface relevant documentation.
Knowledge graphs are an important part of the enterprise AI stack.
They are just not the whole stack.
Different Technologies, Different Contributions
Several technologies have emerged to address various aspects of the context challenge.
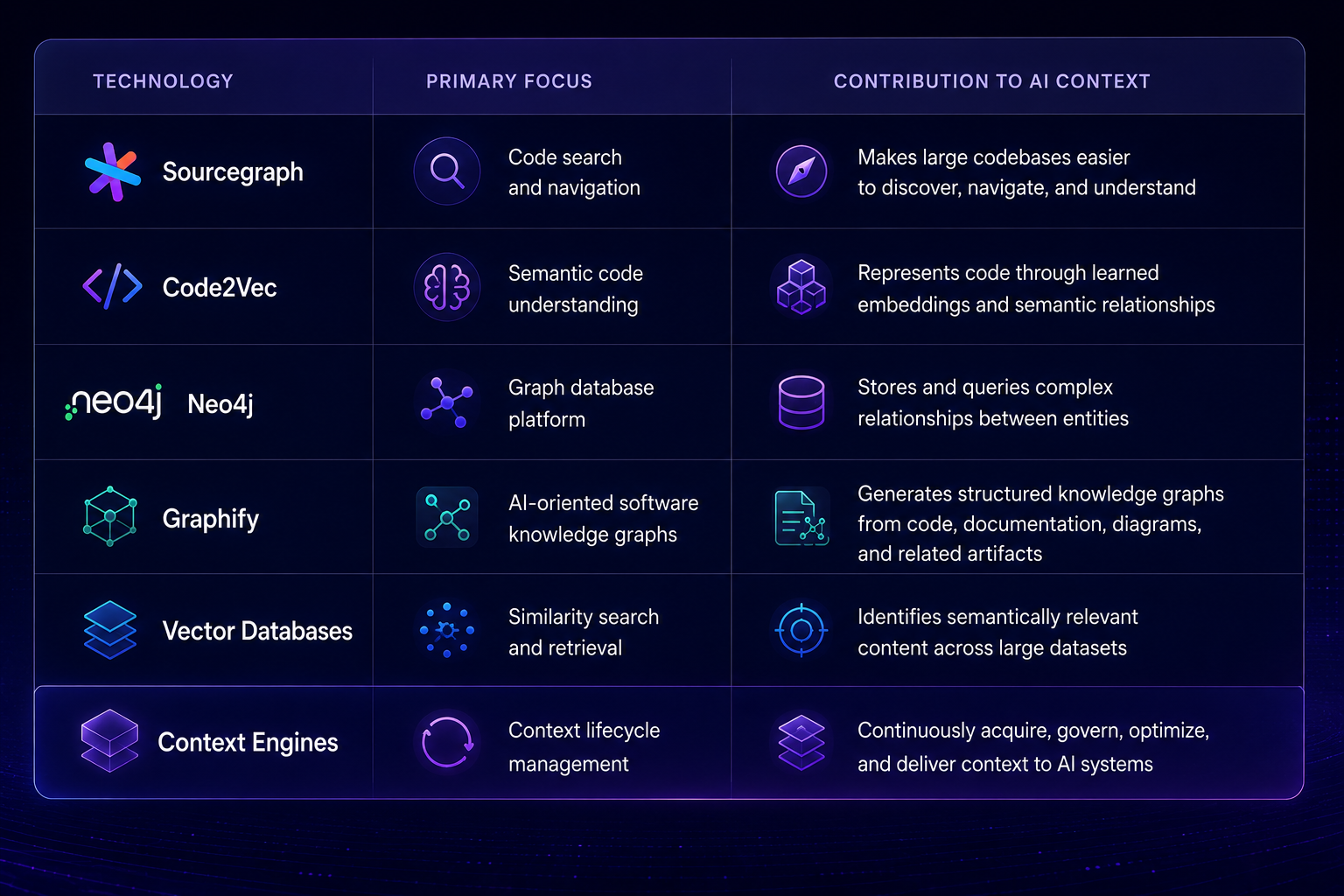
A closer look at Knowledge Graph limitations
Graph-based systems often highlight impressive token reduction benchmarks. For example, Graphify reports a 71.5× reduction in per-query tokens when compared against loading an entire 52-file corpus directly into a model’s context window.
That result is both legitimate and useful. If the alternative is feeding 123,000 tokens of repositories, papers, and diagrams into a model for every question, then a graph-based representation can dramatically reduce the amount of information required to answer that question.
However, the benchmark also highlights an important distinction between knowledge-centric workloads and coding-agent workloads.
In modern coding agents, the baseline is rarely “read everything.” Tools such as Claude Code, Cursor, and Copilot operate through iterative retrieval. Rather than loading an entire repository into context, they search, localize, read a handful of files, refine their search, and repeat. A debugging task might involve reading 5-10 relevant files rather than hundreds of files across the entire codebase.
The comparison therefore shifts from:
- 123,000 tokens vs. 1,700 tokens
to something closer to:
- 10,000-20,000 targeted retrieval tokens vs. graph-assisted retrieval
At that point, the primary question is no longer compression. It becomes retrieval effectiveness.
Can the system help the model find the right information more quickly?
This is where the distinction between knowledge graphs and context engines becomes more apparent.
A knowledge graph exposes relationships and traversal mechanisms. The model may query neighboring nodes, identify ownership relationships, discover dependencies, or traverse structural connections across the graph.
A context engine approaches the problem differently. Rather than exposing graph primitives directly, it focuses on the intent behind the request. A debugging query, for example, may require symbol lookup, semantic search, code search, architectural relationships, ownership information, or some combination of all four. The retrieval strategy is selected dynamically based on the task.
This difference may seem subtle, but it affects how agents behave in practice.
In our internal evaluations, we observed that models naturally gravitate toward retrieval patterns that resemble how developers already work: searching for symbols, locating files, tracing references, and reading relevant code. Graph-based retrieval can be extremely valuable when understanding relationships between systems, services, teams, and architectural components. But for many day-to-day engineering questions, the model’s first instinct is not graph traversal—it is localization.
This does not diminish the value of knowledge graphs. In many environments, graph-derived relationships provide critical context that would be difficult to discover through search alone.
Rather, it illustrates a broader point: reducing tokens and representing relationships are important parts of the context problem, but they are not the entire problem. The larger challenge is determining which retrieval method is most appropriate for a given question and assembling the resulting information into context the model can use effectively.
Where the Context Problem Gets Bigger
The hard part is not only knowing that relationships exist. The hard part is turning the right information into usable, governed, up-to-date context at the moment an AI assistant needs it.
Consider a large engineering organization with thousands of repositories, tens of thousands of documents, hundreds of internal services, multiple ticketing systems, several documentation platforms, strict permissions, and teams spread across business units.
A knowledge graph may be able to represent many of the relationships in that environment. But the AI assistant still needs answers to a different set of questions:
- Which systems should be connected in the first place?
- Which artifacts are relevant to this specific task?
- Which documents are authoritative?
- Which information is stale?
- Which content is duplicated across tools?
- Which data is the user allowed to access?
- How should the context be compressed or summarized?
- How much context can fit into the model’s available window?
- How should context change depending on the model, workflow, or agent?
These are not just graph problems. They are context lifecycle problems.
A graph can tell you that two things are related. A context engine has to decide whether that relationship should be used, whether the underlying information is current, whether the user is authorized to see it, and how to deliver it to the AI system in a form the model can actually use.
What a Full Context Engine Adds
A context engine includes knowledge representation, but it also includes the operational capabilities required to make context work in production.
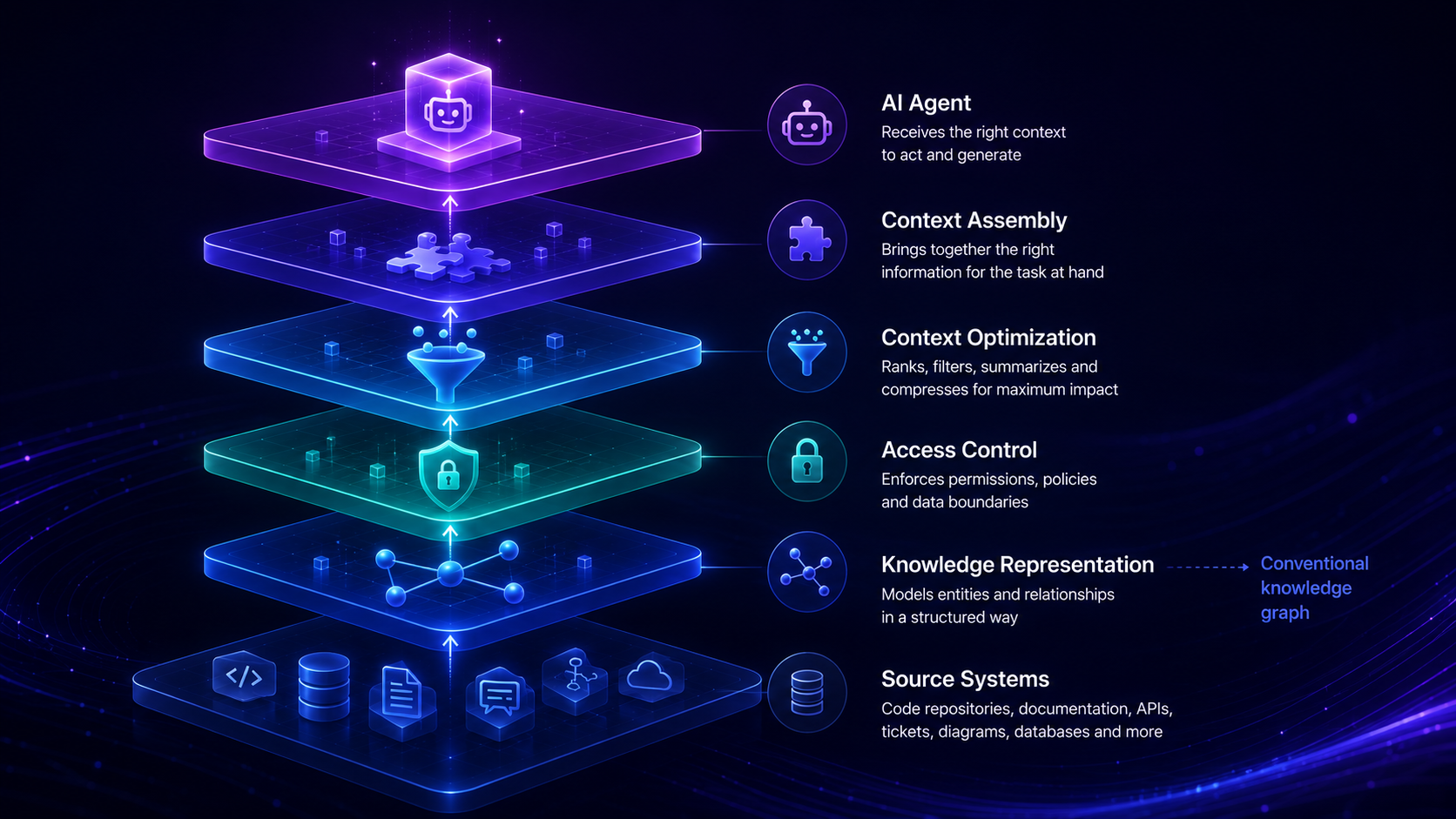
Continuous updates
Enterprise software environments change constantly. Code changes. APIs evolve. Documentation gets rewritten. Tickets move through workflows. Teams reorganize. Ownership changes. Security policies are updated.
A static or periodically refreshed graph is not enough for many AI use cases. A context engine needs to continuously ingest changes from the systems where engineering knowledge lives and keep its understanding current.
Freshness matters because stale context can be worse than no context. An AI assistant that relies on outdated API documentation, old ownership data, or deprecated architecture guidance can easily produce incorrect or risky recommendations.
Access controls
Context is not useful if it bypasses enterprise permissions.
Engineering organizations often have strict boundaries around source code, customer data, regulated systems, internal documentation, and business-sensitive projects. Different developers, teams, contractors, and business units may have different access rights.
A context engine needs to enforce those permissions before information reaches an AI model. It must respect the user’s authorization, apply governance policies, and prevent restricted content from being retrieved or injected into prompts.
A knowledge graph can model access relationships, but the broader context system has to enforce them at runtime.
Prebuilt integrations
Enterprise context does not live only in code repositories.
It lives in GitHub, GitLab, Bitbucket, Jira, Linear, Confluence, Notion, Google Drive, Slack, service catalogs, API registries, CI/CD systems, observability platforms, security tools, internal wikis, and custom systems that have grown inside the organization over years.
A context engine needs integrations into these systems so it can gather context from the places where engineering work actually happens.
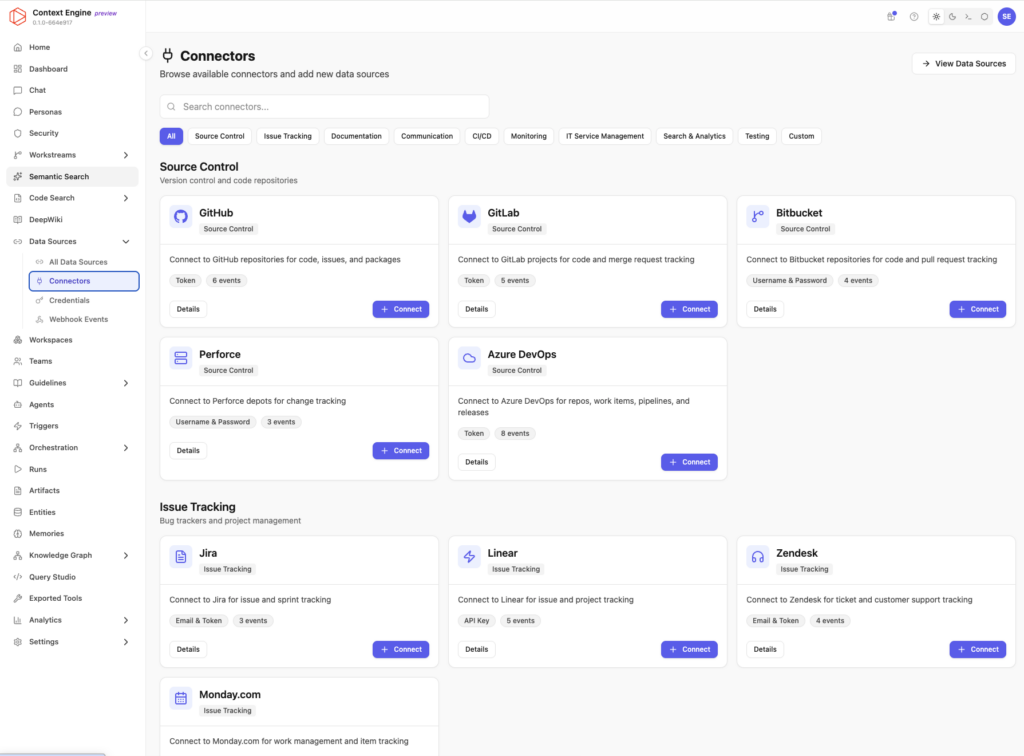
This is one of the reasons context engines are broader than code intelligence tools or graph databases. The goal is not just to understand source code. The goal is to connect the full body of knowledge that developers and AI agents need to work effectively.
Context selection
More information is not automatically better.
An AI assistant working on a test failure does not need every document, ticket, dependency, and service relationship connected to a repository. It needs the subset that is relevant to the task.
A context engine must rank, filter, and select information based on the user’s request, the active codebase, the workflow, the available model, and the constraints of the context window.
This is where raw retrieval often falls short. The system has to make judgment calls about what to include, what to exclude, and what to compress.
Context optimization
Enterprise knowledge is rarely model-ready.
Documents may be long, repetitive, outdated, or formatted for humans rather than AI systems. Code may need to be chunked. Tickets may need to be summarized. API documentation may need to be transformed into a more compact representation. Duplicate information may need to be removed.
A context engine prepares information before it is delivered to the model. That can include summarization, deduplication, ranking, compression, metadata enrichment, and format transformation.
The objective is not simply to retrieve relevant information. It is to deliver usable context.
Runtime delivery
Different AI workflows require different context strategies.
A code completion request, a test generation task, a security review, a migration plan, and a multi-step agentic workflow all need different kinds of context. They may also use different models with different context windows, latency requirements, and reasoning capabilities.
A context engine needs to assemble and deliver context dynamically based on the workflow being performed.
This runtime layer is what turns stored enterprise knowledge into practical AI assistance.
Knowledge Graphs and Context Engines Are Complementary
None of this diminishes the value of knowledge graphs.
In fact, knowledge graphs can be an important component of a context engine. They provide structure, expose relationships, and help AI systems understand how software artifacts connect across an organization.
The issue is category confusion.
A graph database, code graph, or software knowledge graph can help represent part of the enterprise knowledge landscape. A context engine is responsible for the larger system around that representation: ingestion, integrations, freshness, permissions, relevance, optimization, and delivery.
Put another way:
A knowledge graph helps answer, “How are these things connected?”
A context engine helps answer, “What does this AI assistant need right now, is the user allowed to access it, is it current, and how should it be delivered?”
Both questions matter. They are just different questions.
Why This Matters for Enterprise AI
As organizations move from AI experiments to production deployments, context becomes an operational requirement.
It is not enough for an AI assistant to understand a repository in isolation. Enterprise developers work across systems. They rely on documentation, tickets, service ownership, architecture decisions, compliance rules, APIs, infrastructure, and team knowledge. Much of that context lives outside the codebase.
This is why a complete context engine needs to connect to all relevant engineering artifacts, not just source code. It must continuously update as those artifacts change. It must enforce access controls. It must integrate with existing systems. It must decide what information is relevant for a given task. And it must deliver that information efficiently to the AI tools developers use.
Knowledge graphs help with one important layer of that problem: representation.
Context engines address the broader lifecycle.
For enterprise AI coding assistants, that broader lifecycle is what determines whether an assistant can move from impressive demos to reliable day-to-day use.